前言
研究生阶段入坑了硬盘故障预测的相关研究,并在导师与博士学长的引导下参与了几个大大小小的相关项目,这里记录一下学习心得,并提出一些自己的疑问,在留给自己以后温习的同时也希望能对看到这篇博客的人有些许帮助,不足之处欢迎不吝赐教,疑问处若有共鸣也希望能讨论交流!
现状
现在绝大部分关于硬盘故障预测的研究都或多或少使用了人工智能的技术,包括:
- 传统机器学习方法,在我读过的大部分论文中, RandomForest(随机森林)都有很好的表现,也是我当前常用的基础模型。
- 神经网络,如 LSTM 等,这部分我涉猎很少,就不献丑了。
- 特殊的神经网络模型,如 GAN,这也是我下一步准备的一个研究方向,目前已有研究者通过使用 GAN 巧妙地解决硬盘故障预测中的“冷启动”问题,我觉得这在实际的生产环境中有较高的应用价值,关于这点我会专门写一篇博客进行讨论并验证其实用性,当然啥时候能写出来也完全取决于我的研究进度了。。。。
既然使用了人工智能模型,那必然会有相应的数据集。目前来说,最常用的、且与硬盘故障强相关的特征属性就是SMART。当然也不断有研究者提出新的与硬盘故障相关的特征属性,如硬盘故障的时空局域性等等,这里不再赘述。
这篇文章主要基于传统机器学习方法与硬盘的 SMART 属性来展开,演示模型为 RandomForest,数据集使用开源数据集 BackBlaze。
数据预处理与模型调优的关系
常用的数据预处理手段包括数据清洗、样本均衡、标准化等,面对一些非数值型的数据,如Firmware,还需要进行数据编码,常用的编码方式有标签编码、独热编码等。此外,还可以通过计算获得新的特征列。例如计算某个属性的增量、计算两个属性的比值等,某些通过计算得到的新属性也对故障预测有很大帮助,打个比方:盘的坏块会随着使用时间增加而增加,当某一时刻坏块的数量激增,这就可能意味着硬盘即将损坏。
那么数据预处理与模型调优又有什么关系呢?在实验过程中我发现,常规的调优手段(如交叉验证、网格搜索等)对模型预测效果的影响十分有限,反而训练样本的一些属性对模型的性能影响更大,这里首先介绍几个概念:
- 训练集、测试集:训练集用来训练模型、测试集用来测试模型的性能。这里面还会涉及到验证集的概念,验证集用来选择最佳的超参数组合,与交叉验证也有关,这里不再赘述。
- 正样本、负样本:这里的正样本指故障盘的数据样本、负样本则是正常盘数据样本。
- 预测窗口:这个概念十分重要,它不仅可以帮助扩充训练数据集的大小,对模型性能的影响也很大。

从图中不难看出,随着硬盘的使用,硬盘会不断趋向故障。于是提出预测窗口这个概念,在预测窗口内的数据均视为故障数据、预测窗口前的数据均视为正常数据,这样做还可以一定程度上扩充故障样本数量。下面将会展示部分实验数据解释这些样本属性与模型性能调优的关系。
首先是分析正、负样本比例与模型性能的关系,这里分为3组进行实验,每一组的预测窗口保持一致,正负样本比例取1:1、1:2、1:3、1:5,主要考量召回率、误报率,其中,横坐标的命名方式为w_p_n,w为预测窗口大小,p为正样本比例、n为负样本比例:
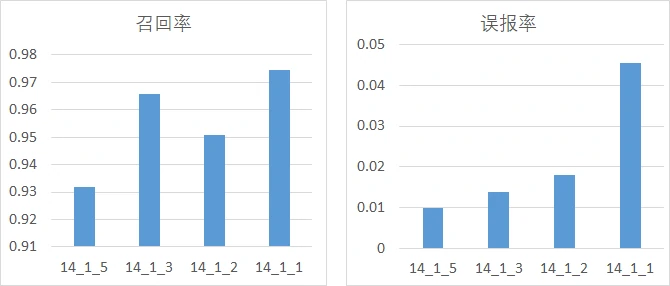
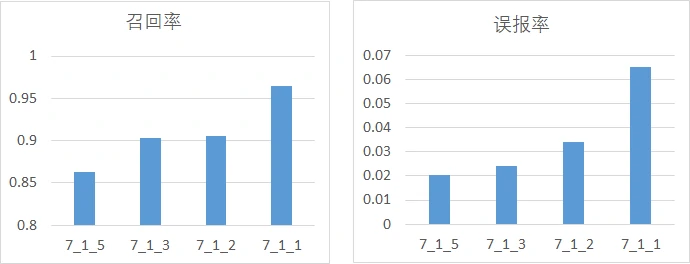
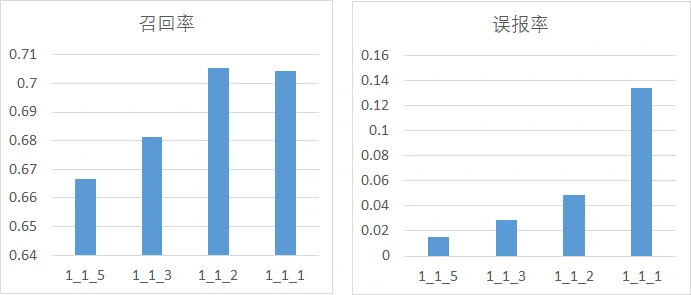
从图中不难发现,随着正负样本比例变大(即正样本占比增加),模型的召回率逐渐上升,模型的误报率也逐渐上升,但是上升的幅度都比较小。
然后分析预测窗口大小与模型性能的关系,这里分为4组实验进行讨论,每组的正负样本比例不变,预测窗口分别取1、7、14:
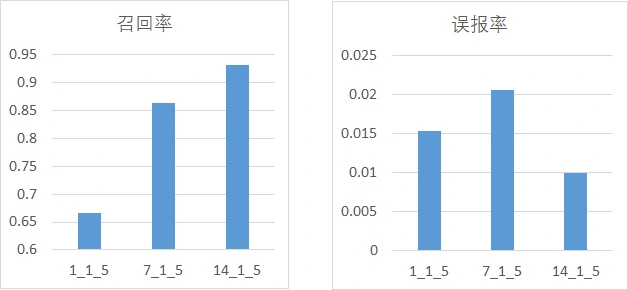
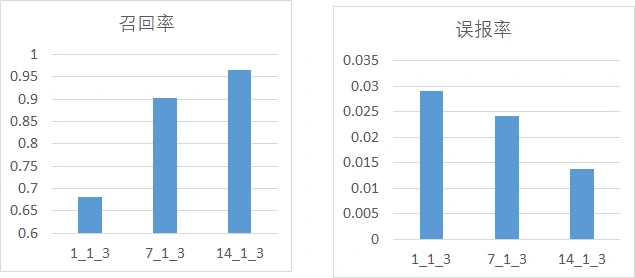
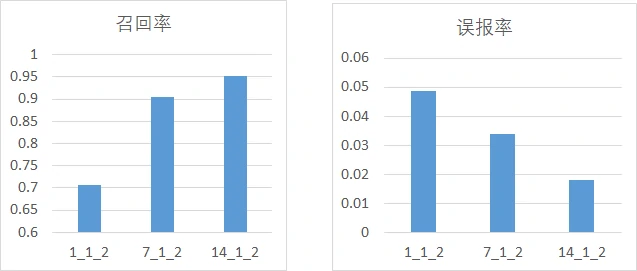
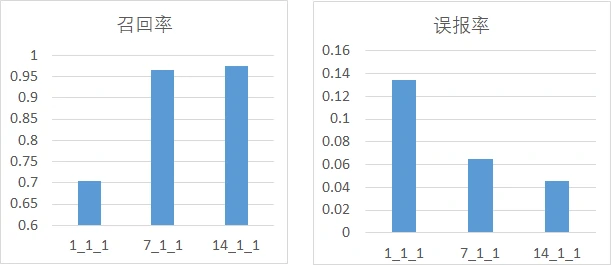
从图中可以看出,仅用故障当天的数据作为故障盘样本会导致模型的性能偏低,导致这一现象的原因可能是因为故障盘预测窗口=1时,故障样本较少,模型无法充分学习故障样本故障样本的特征,从而导致召回率很差。当然预测窗口也不是越大越好,因为预测窗口大小为7和14时的性能差距并不明显,而且样本越多,模型训练也会越慢。
此外,从这些实验中不难看出召回率与误报率是两个矛盾的指标,很难在提高召回率的同时还能降低误报率。加长预测窗口似乎有效,但其带来的收益也比较有限,所以需要折中选择最合适的样本处理方案。不过也有研究者通过多模型的投票机制降低了甚至避免了误报,但这会带来相当大的模型训练与运行开销。
关于模型有效性的思考
硬盘故障预测是一种有相当风险的技术,不能百分百依赖故障预测的结果,数据冗余备份和恢复等手段是不可或缺的。在实验过程中我发现,尽管模型在训练的过程中表现良好(达到95%以上的召回率),但在实际预测过程中表现却很差(召回率低于60%)。例如,我们使用1月~11月的数据训练模型并达到95%的召回率,然后去预测12月的数据。这时召回率会骤降30%左右。根据现有经验分析其可能的原因:
- 模型训练时发生过拟合,但这种可能性很小。
- 模型训练未考虑到数据样本的时序性。因为例如SMART之类的特征,他的值是随时间递增的,在使用传统方法训练模型时,我们经常会对样本进行随机分割(train_test_split等)、随机抽样(smote等),这样会打乱样本的时序,造成这样一种结果:使用未来数据训练模型,用历史数据测试、调整模型。这样训练出来的模型当然对未来数据的预测效果很差。后面我会专门讨论基于时序的模型训练,并给出相应的实验数据。
- 可能还有其他原因,后续再补充。
模型的有效性是一个值得深究的问题,我们当然可以仅通过传统的训练方式得到非常优秀的实验数据,但从实际应用的角度来说毫无意义,而且也经不起的推敲。
就先到这。。。