简介
由于做故障预测的相关研究经常要分析原始数据,每次都要写代码比较麻烦,所以考虑用数据分析软件来做。但目前市面上的数据分析软件功能普遍比较复杂且不符合要求,所以打算自己定制一个数据分析程序,供以后研究学习使用。根据自己的需求可以随时追加各种数据分析方法。详细代码见:Ruabit18/Data_Analyze: 数据分析 (github.com)
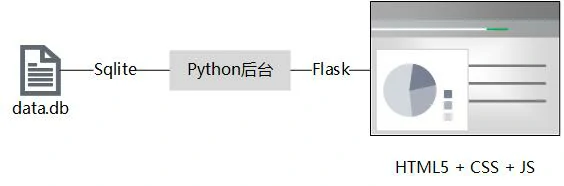
程序的整体框架图如下:
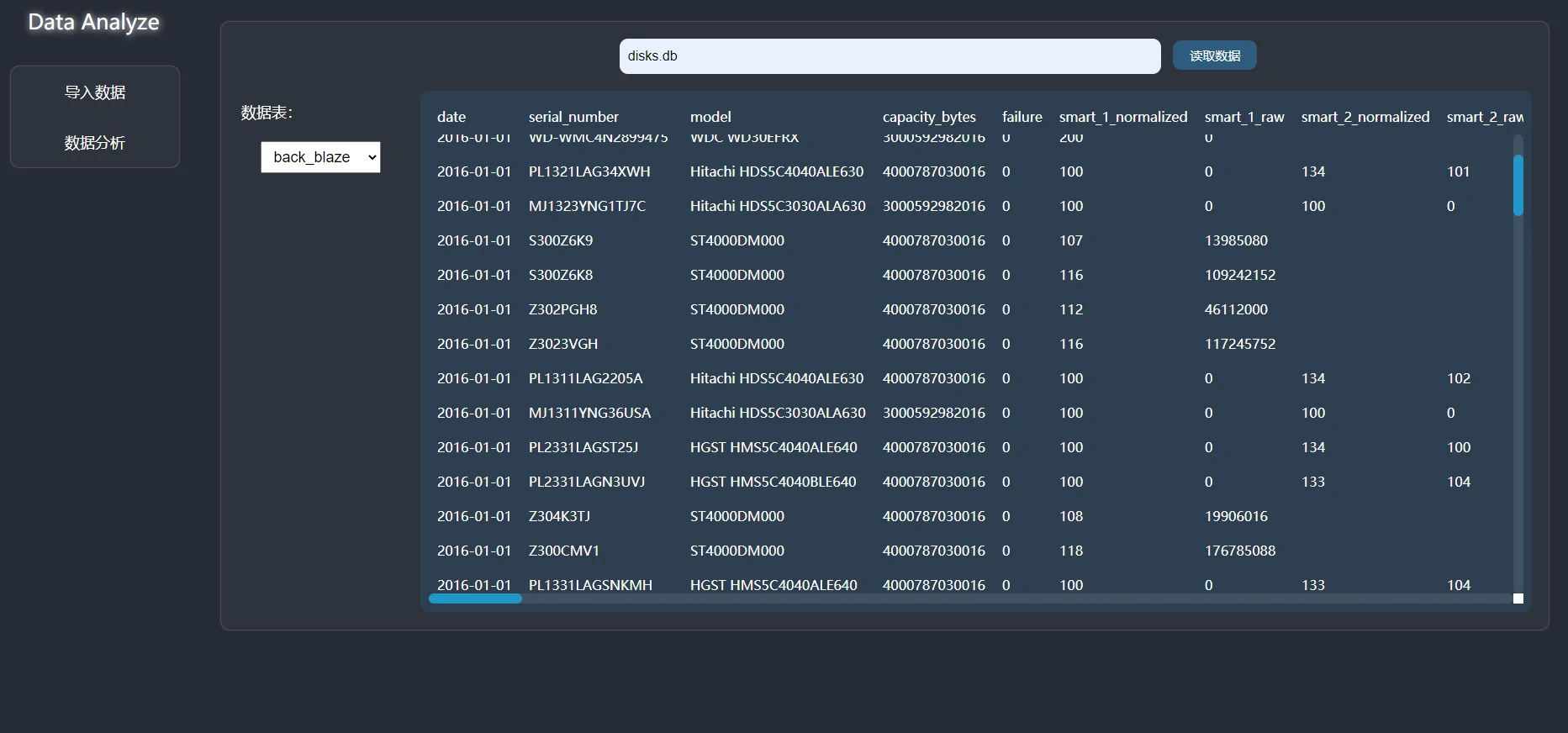
程序的运行界面如下:
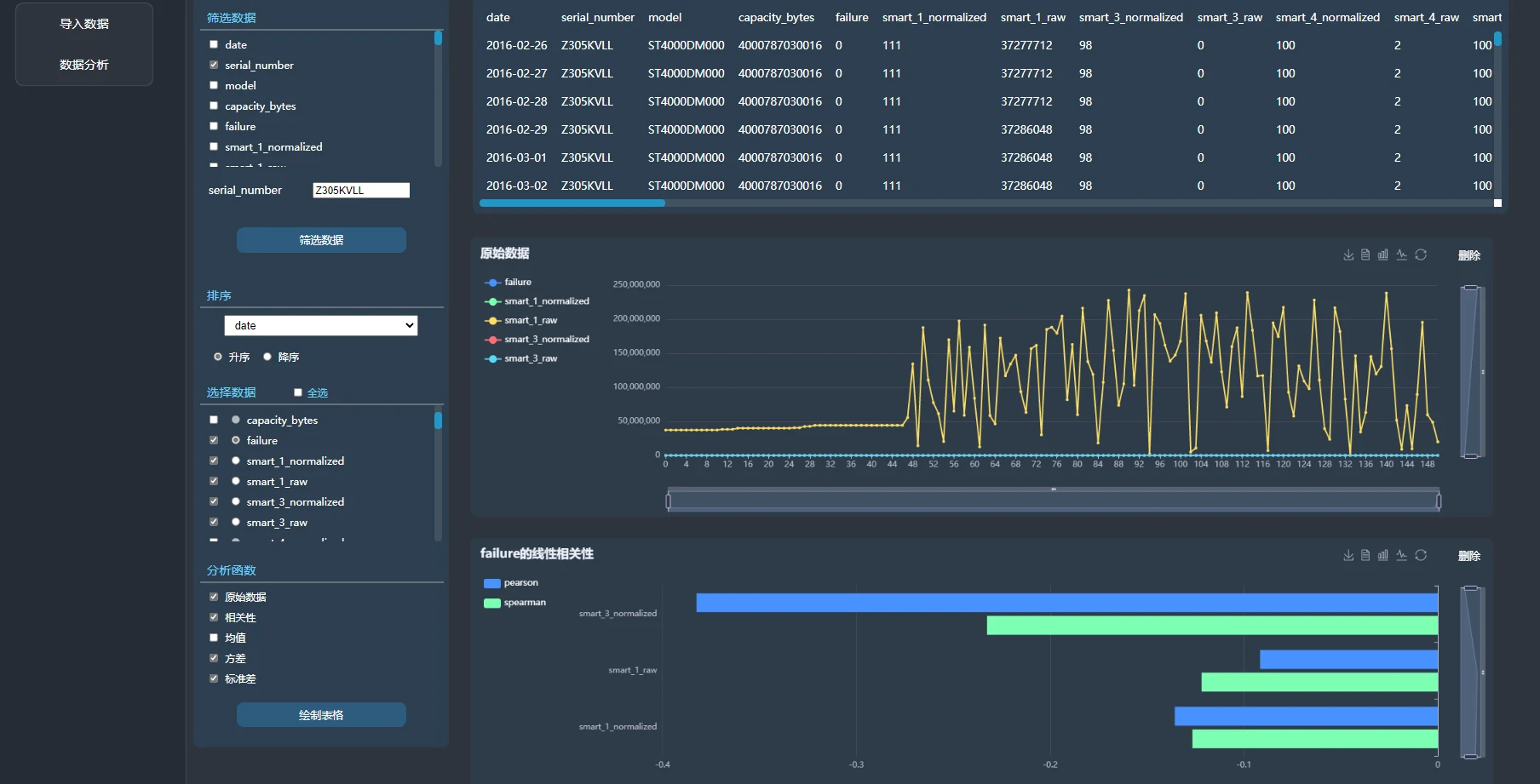
用到的编程语言有:
- Python(3.9):负责将原始数据入库、提供数据访问接口、提供数据分析方法。使用的库主要有Sqlite3、Pandas、Flask。
- HTML5 + JS + CSS:这部分负责数据的展示、提供操作面板。主要用到了ECharts图表插件。
实现步骤
一、数据访问层——SQLite
SQLite
SQLite是一种轻型数据库,是遵守ACID的关系型数据库管理系统。它的特点是数据库管理程序集成在代码中,不需要安装额外的程序,数据库与数据表均以文件的形式保存在一起。同时也有相应的可视化工具来方便管理,如SQLite Studio等。
- 数据库引用与创建
1
2
3
4
5
6
7import sqlite3
def connect(self):
db_path = os.path.join(db_root, self.db_name_)
print('Connecting DB: ', db_path)
conn = sqlite3.connect(db_path) # connect会自动创建不存在的数据库文件
return conn- 数据库语句执行
这里以数据库查询为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25def select(self, values:list = [], keys:dict = {}, order:list = None, limit:tuple = None, chunksize:int = None) -> DataFrame:
conn = self.connect()
# 组装SQL语句
if len(values) == 0:
return None
sql = 'select '
sql += ','.join(values) + ' from %s' % self.table_name_ # 选择要筛选的列
if len(keys) > 0: # 设置筛选条件
sql += ' where %s' % ' and '.join([key + '=\'%s\'' % value for key, value in keys.items()])
if order != None and len(order) == 2: # 设置排序规则
sql += ' order by \'%s\' %s' % (order[0], order[1])
if limit != None and len(limit) == 2: # 查询结果长度限制
sql += ' limit %d offset %d' % limit
print('execute sql:', sql)
try:
# pandas的read_sql()可以将查询结果转换为DataFrame,十分方便
result = pd.read_sql(sql=sql, con=conn, chunksize=chunksize)
except Error as e:
print(e)
return None
return result数据入库
原始数据来自BackBlaze采集的硬盘故障数据,文件格式为.csv,数据格式如下:

将全部csv文件导入数据库:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22def csv_to_sql(db_name, table_name, data_path:str, target_file:str = '.csv', max_depth:int=3):
sqlite_tools = Sqlite_Tools()
sqlite_tools.set_db(db_name=db_name)
sqlite_tools.set_table_name(table_name=table_name)
start_depth = len(data_path.split(sep=sys_sep))
for root, dirs, files in walk(data_path):
search_depth = len(root.split(sep=sys_sep)) - start_depth + 1
if search_depth > max_depth:
print("超出最大深度,停止搜索.")
return
for file in files:
if os.path.splitext(file)[1] == target_file:
csv_path = os.path.join(root, file)
print('writing: ', csv_path)
sqlite_tools.create_table_by_csv(csv_path=csv_path)
def create_table_by_csv(self, csv_path):
conn = self.connect()
df = pd.DataFrame(pd.read_csv(csv_path, encoding='utf-8'))
# 读取CSV文件为dataframe,使用to_sql()将dataframe写入数据库
df.to_sql(name=self.table_name_, con=conn, if_exists='append', index=False)
二、业务逻辑层——Flask
Flask
Flask是一个使用 Python 编写的轻量级 Web 应用框架,使用Flask能很方便的实现前端与后台的交互流程,这里将 Flask 框架用于本地应用程序。详细资料参考Flask 中文文档 (2.0.1)。
使用Flask实现简单业务逻辑
初始引用及配置
1
2
3
4
5
6from flask import Flask, json, render_template, request, jsonify
from flask_cors import CORS
import webbrowser
# 初始化后台
app = Flask(__name__, template_folder='./ui/html') # './ui/html'为HTML文件根目录
CORS(app, resources=r'/*') # 运行时可能遇到跨域访问错误,这行代码允许所有与访问创建一个微服务程序,类似于 Java 的 Servlet
1
2
3
4
5
6
7
8
def show_tables():
db_name = request.form.get('db_name', type=str, default=None) # 获取请求中的参数
sqlite_tools.set_db(db_name=db_name)
result = {}
result['tables'] = sqlite_tools.show_tables()
return jsonify(result) # 响应请求,返回处理后的信息启动 Flask 后台
1
2
3if __name__ == '__main__':
webbrowser.open(path.join(path.curdir, 'ui/html/main.html'))
app.run(host='0.0.0.0', port=5000) # ip:port 可以自由设置举一个简单的请求微服务的例子
1
2
3
4
5
6
7
8
9$.ajax({
url: 'http://127.0.0.1:5000/show_tables', // show_tables 必须保持一致
type: 'post',
dataType: 'json',
data: send_data,
success: function(data){
// 后台 retrun 的数据在这处理
}
})
三、表示层——HTML5
前端编程我只是略懂,稍微会做点简单的网页,这里就不献丑了,列举几个常用的网站: